
Supplementing your hardware alarms with the right software alarms is a vital part of a condition monitoring approach that “manages by exception”.

This vibration monitor dates back to the late 1960s and is an example of a device with only a single setpoint. Most monitors today have at least two setpoints: alert and danger.
While the very earliest vibration monitoring hardware often had only a single alarm setpoint, it wasn’t long before users and manufacturers alike realized such an approach was inadequate. They discovered that at least two setpoints were necessary: (sometimes called “HI” or “pre-trip”) and danger (sometimes called “HI HI” or “trip”). While a single setpoint was certainly better than none and could be used for a trip, that approach meant a pre-trip warning was not available and thus no indication that corrective intervention should occur to avoid a trip altogether.
Conversely, if the single setpoint was used for an alert, operators could be advised of a condition before it reached destructive levels, but could not automatically protect the machine if conditions further degraded so quickly that human intervention to manually trip the machine was impossible. For example, a thrust bearing failure can incur catastrophic damage in the space of a few seconds, much faster than a human can register and respond.
For a while, as the use of microprocessors became commonplace in instrumentation, the pendulum swung the other direction: hardware capable of a multitude of alarm setpoints. These alarms were often more than just level-based and represented complex logical combinations and mathematical operations such as averaging and rate-of-change. While such efforts were well-intentioned, they often resulted in an avalanche of erroneous alarms under conditions that were “normal” but represented changes from steady-state conditions.
For example, when a machine was brought offline, rate-of-change alarms triggered on rapidly changing vibration levels would trigger. While such alarms were indeed valid under steady-state conditions, they were not valid under changing machine speeds such as shutdown rpm profile. As a result, the alarm panel would flood with spurious indications. Or, a process condition might change – such as the mol weight of gas in a compressor, or a load change on a generator – and a rapid transition in vibration to “new normal” levels might occur. While the rate of change might be abnormal under steady-state conditions, it could be entirely consistent with a normal change in operating conditions and therefore not a cause for concern.
These two very simple examples serve to underscore that as more and more alarms are added to a system, care and thought must be taken. This is particularly important when the alarming is implemented at the hardware level because these are typically the alarms seen by operators on their annunciator panels and/or DCS screens. When an operator begins experiencing too many spurious alarms, they will develop a predictable but ultimately counterproductive scepticism that alarms are to be validated first and only then acted upon. The first response thus becomes “faulty instrumentation” rather than “faulty machine”.

Alarm “acknowledge” buttons such as this were quite common in control room panels of the past and can still be found in many plants. Operators acknowledging alarms because they perceive them to be “nuisance” or “spurious” as opposed to legitimate is a sure-fire sign that a particular alarming strategy has become ineffective
One industry veteran that was interviewed in the preparation of this article recalls a control room from years ago where the operators had actually jammed a popsicle stick into the alarm acknowledge button as their way of dealing with spurious alarms. Although an extreme example, it serves to underscore that once personnel have lost confidence in the integrity of alarms, a plant may as well not have any alarms at all – alarms that do occur will be dismissed as illegitimate.
So, if a single alarm is insufficient, but too many alarms can be counterproductive, what is the “right number” of alarms and where should they reside – in hardware or software?
These are actually two separate – but interrelated – questions and will be addressed as such.
First, where should an alarm reside?
If the alarm meets the following two criteria, hardware is the appropriate location:
“…what is the ‘right number’ of alarms and where should they reside – in hardware or software?”
Let’s take a simple example of an alarm meeting the above two criteria<. Imagine that you are monitoring a hydro turbine generator that runs through a “rough load zone” (RLZ) during start-up and as wicket gates are adjusted. This is an example of a mechanical issue that does not manifest as a simple elevation of overall (unfiltered) vibration levels. Operators and OEMs have learned that so-called RLZ manifests as broad-band vibration at most frequencies except 1X (i.e., the vibration frequency coinciding with shaft rotational speed).
A measurement known as “NOT 1X” is routinely used to detect the presence of a rough load zone and operators actively use this reading to ensure they do not leave the machine in an RLZ state for any length of time. This measurement meets the two criteria: it is available in the hardware (such as a VM600 MPC4 Mk2 channel) and it is used by operators to make changes in the operating condition of the machine.
Now, for purposes of contrast, let’s consider an alarm type that would not necessarily be appropriate for implementation in hardware: an exhaust fan subject to frequent imbalance due to the build-up of particulates on the blades. Although most monitoring hardware can indeed return a 1X vibration amplitude along with overall vibration, experience may have shown that rising 1X levels are almost always associated with this build-up and not cause for concern. When caught early, maintenance is simply scheduled to clean the blades and return the fan to service.
Operators cannot make changes to the fan to counteract the condition, and thus even though the measurement could conceivably be accomplished in the hardware, an alarm in that location would not give any meaningful guidance to operators. Instead, such an alarm should be delivered to maintenance personnel and rotating machinery personnel or vibration analysts. The vibration analyst would first look at corroborating data to ensure the change in 1X vibration was entirely consistent with imbalance – and not some other malfunction – and then when validated would issue a work order for maintenance personnel to take the fan briefly out of service to clean the blades.
Another consideration for hardware versus software alarms pertains to visibility and latency. If an operator is going to rely on an alarm to take some type of intervening action with the machine in a real-time or quasi-real-time environment, then hardware-based alarms are generally appropriate due to the speed at which they can be detected and annunciated. In contrast, if a software-based alarm represented a latency of even 15 seconds, due to computation times for complex rules and then transmission via a digital protocol such as Modbus or Profibus or OPC to a DCS with a scan time measured in seconds instead of milliseconds, this may indeed represent an unacceptable delay for the operator to take action.
Next, we examine the second part of the question: how many alarms are appropriate?
In general, a software alarm should be provided for every parameter with a hardware alarm, allowing rotating machinery personnel to be aware of a condition – such as high radial vibration or abnormal thrust position – before a hardware alarm triggers. This is precisely what we mean by “managing below the alert level” because the vibration analyst or rotating machinery engineer can be alerted to issues that are detectable and trending in the wrong direction, but not yet serious enough to meet the threshold of a hardware-based alarm. This allows a proactive response to hopefully discover the root cause and remedy the situation before it ever progresses.
In addition to implementing “pre-alert” alarm levels in software, it is also useful to provide additional alarm levels in the condition monitoring software for parameters not measured within the protection system. Let’s use the example of a rolling-element bearing that typically takes 6 months to fail from the time that earliest warning occurs due to an increase in amplitude at ball spin frequency (BSF), inner race ball pass frequency (BPFI), or outer race ball pass frequency (BPFO). Because the so-called PF interval (or time between detection and functional failure) is adequately long, a software-based approach is entirely justified.
Thus, while a machine with rolling element bearings might warrant continuous protection based on overall vibration levels, it does not necessarily need hardware-based alarms on every bearing-related frequency. This is because experience has shown such failures to progress gradually rather than suddenly. In contrast, protection parameters based on overall vibration, bearing temperature, lube oil temperature, and lube oil pressure might be warranted for the particular machine because measurements outside of normal bounds for any of those parameters could indicate that sudden failure is imminent.
The guiding principle for software-based alarms thus becomes two questions:
If a software alarm can be implemented while satisfying the above two criteria, it will be useful. It will thus not matter whether it takes two software-based alarms or twenty software-based alarms to be proactive. Choose the least number that satisfies the objective so that the “care and feeding” of alarm setpoints does not become a full-time job in and of itself.
Just because a measurement can originate in the hardware does not mean that its alarm must likewise originate in the hardware. As has been noted, it may be perfectly appropriate to have measurements for which no corresponding hardware alarms have been established. Our VibroSight suite of applications provides an extensive ability to establish alarms on both directly measured and computed variables and so-called “virtual” variables. A virtual variable is one made up of two or more other variables into a composite measurement. One example might be the average of several direct readings. Another might be a variable that looks for the presence of three conditions and is “true” when they are present and “false” when they are not simultaneously present. Users are generally limited only by their imagination based on a very extensive set of mathematical and logical operators within VibroSight.
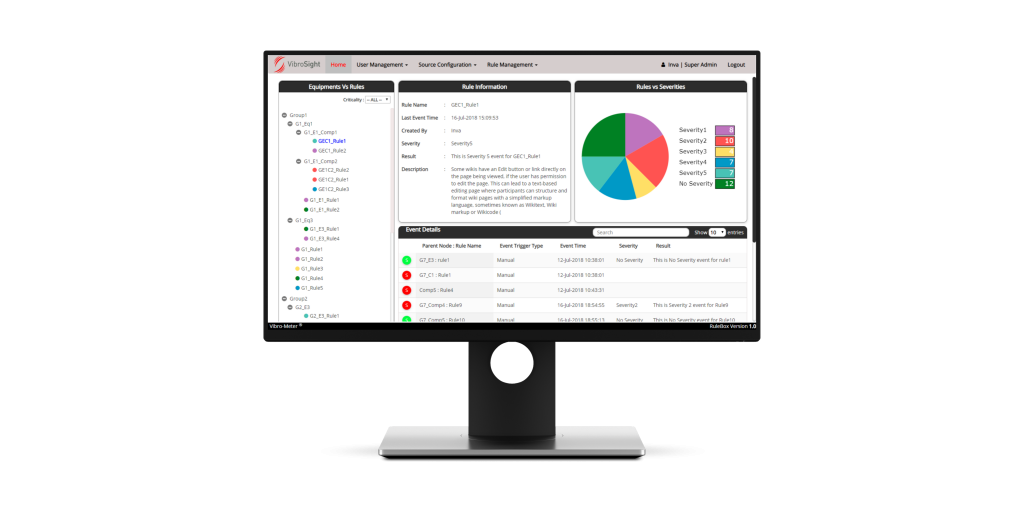
VibroSight’s diagnostic rule box software provides an intuitive user interface that can be used by machinery/process operators – not just machinery specialists. It summarizes the status of all machinery in a collapsible tree hierarchy, uses multiple severity levels for sufficient granularity (six levels) ranging from extreme to none, and provides easily understandable, customizable advisories whenever a machine fault is detected by the system’s embedded intelligence.
Lastly, in addition to the basic alarming capabilities in vibro-meter’s hardware and software, the Diagnostic Rule Box component of VibroSight software can be an extremely powerful way to both automatically analyze condition monitoring data and to give intelligent advisories to both operations and maintenance personnel. In other words, it can help not just create additional, powerful alarms, but to provide meaning and context to such alarms through intelligent messaging that guides personnel on the alarm severity, alarm location, and alarm response.
You can learn more on our VibroSight Landing Page, or by contacting your nearest vibro-meter sales and service professional.
VibroSight is vibro-meter’s fast, powerful and user-friendly machinery protection and condition monitoring software that enables the reliability and operational efficiency of industrial machinery to be optimised through the use of advanced predictive-maintenance methodologies.

VibroSight is vibro-meter’s fast, powerful and user-friendly machinery protection and condition monitoring software that enables the reliability and operational efficiency of industrial machinery to be optimised through the use of advanced predictive-maintenance methodologies.




